
Databricks
Founded Year
2013Stage
Line of Credit | AliveTotal Raised
$19.252BValuation
$0000Last Raised
$2.5B | 6 mos agoRevenue
$0000Mosaic Score The Mosaic Score is an algorithm that measures the overall financial health and market potential of private companies.
+22 points in the past 30 days
About Databricks
Databricks provides a platform for businesses to integrate data and artificial intelligence. The company's main offerings include a data intelligence platform that supports generative artificial intelligence (AI), analytics, data governance, and data warehousing. Databricks serves sectors requiring data management and analytics capabilities, including financial services, healthcare, and media and entertainment. It was founded in 2013 and is based in San Francisco, California.
Loading...
ESPs containing Databricks
The ESP matrix leverages data and analyst insight to identify and rank leading companies in a given technology landscape.
The AI observability & evaluation market provides solutions that continuously monitor, test, and assess AI systems, offering real-time visibility into their behavior. AI performance can degrade when models encounter data different from training sets or operate in new contexts. These solutions identify issues by tracking prediction outliers, measuring accuracy, detecting bias, benchmarking performa…
Databricks named as Leader among 15 other companies, including IBM, Arize, and Datadog.
Loading...
Research containing Databricks
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned Databricks in 25 CB Insights research briefs, most recently on Apr 10, 2025.


Jan 7, 2025 report
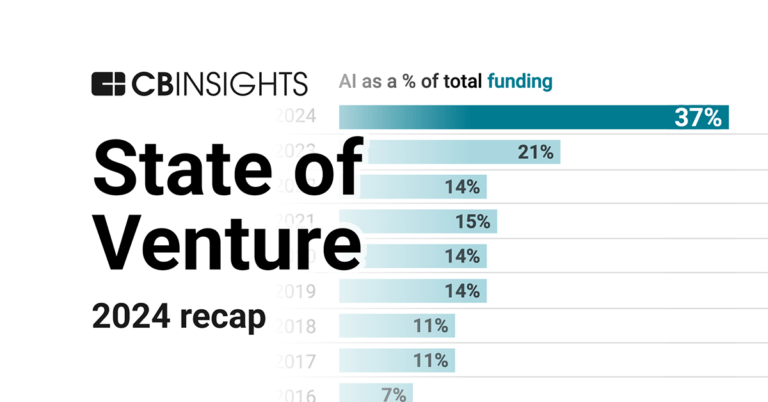
State of Venture 2024 Report
Oct 4, 2024
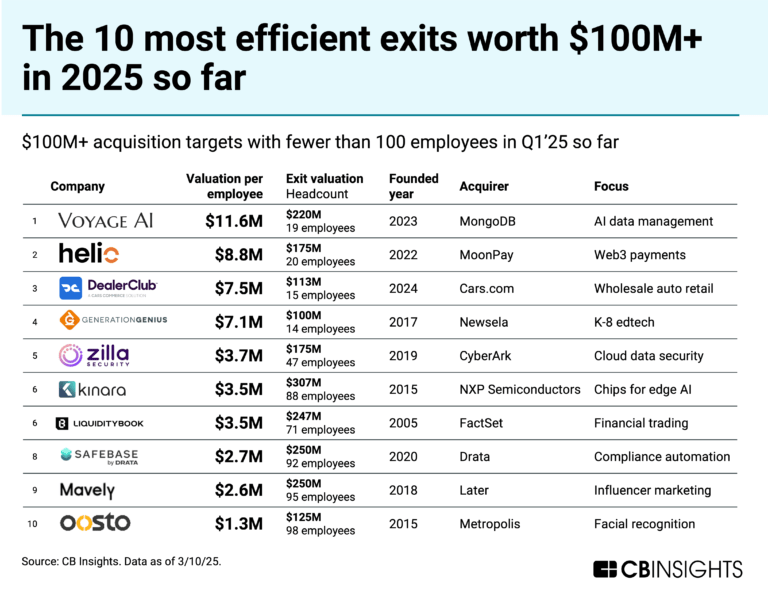
The 3 generative AI markets most ripe for exits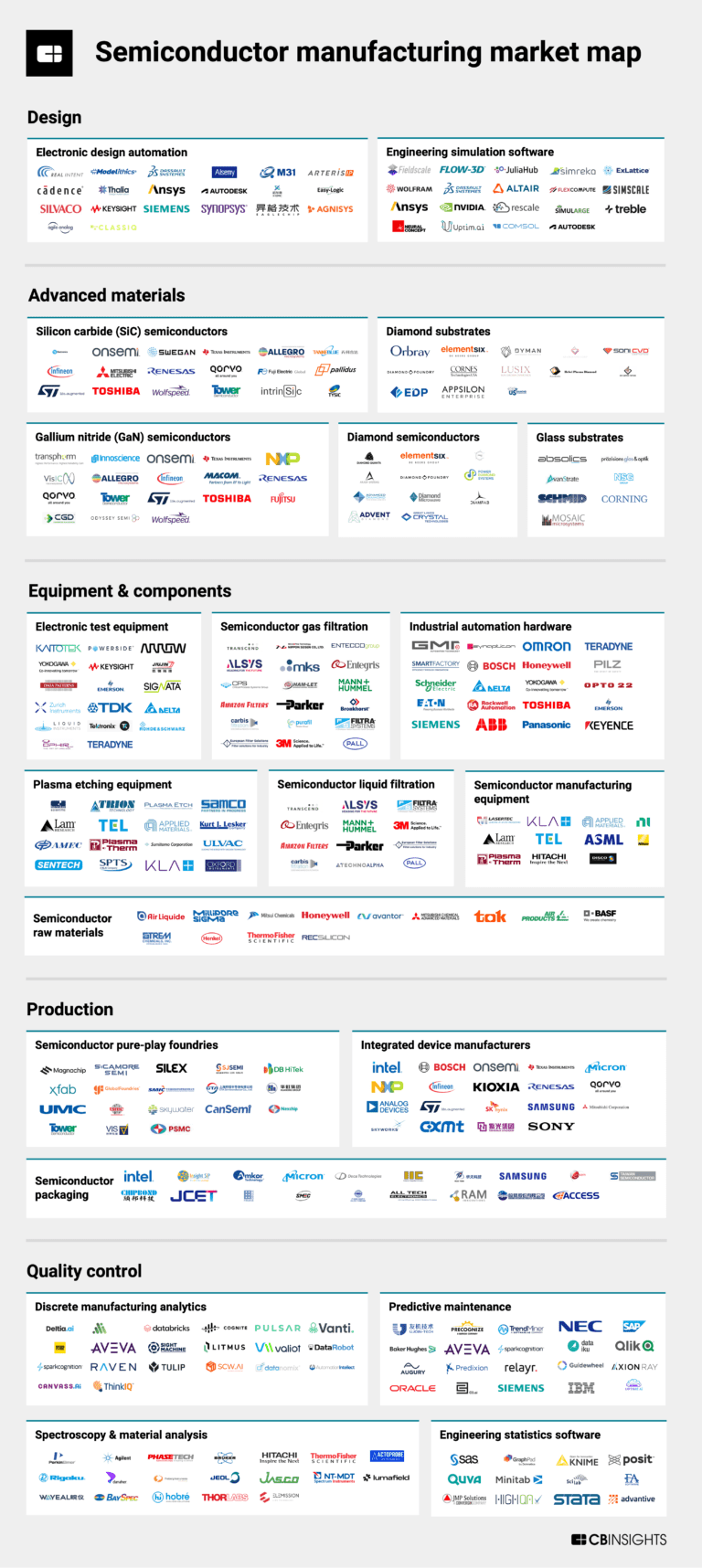
Sep 23, 2024
The semiconductor manufacturing market mapExpert Collections containing Databricks
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
Databricks is included in 8 Expert Collections, including Unicorns- Billion Dollar Startups.
Unicorns- Billion Dollar Startups
1,276 items
Tech IPO Pipeline
825 items
Advanced Manufacturing
6,695 items
Companies in the advanced manufacturing tech space, including companies focusing on technologies across R&D, mass production, or sustainability
Generative AI
2,332 items
Companies working on generative AI applications and infrastructure.
AI 100 (2024)
100 items
Artificial Intelligence
10,050 items
Databricks Patents
Databricks has filed 98 patents.
The 3 most popular patent topics include:
- data management
- database management systems
- diagrams

Application Date | Grant Date | Title | Related Topics | Status |
|---|---|---|---|---|
9/26/2023 | 3/25/2025 | Data management, Data security, Parallel computing, Computer security, Information technology management | Grant |
Application Date | 9/26/2023 |
|---|---|
Grant Date | 3/25/2025 |
Title | |
Related Topics | Data management, Data security, Parallel computing, Computer security, Information technology management |
Status | Grant |
Latest Databricks News
Jul 9, 2025
The Snowflake vs. Databricks War and The Shift Towards Federated IT July 9, 2025 Snowflake Databricks Federated IT strategies prioritize open catalogs, interoperability, and vendor-agnostic architectures for scalable, secure data access. Organizations have been locked in an ongoing debate over whether Snowflake or Databricks provides the superior data platform. Both companies have developed impressive ecosystems, offering analytics, AI capabilities, and data engineering solutions. However, these platforms often require organizations to move or transform large volumes of data into proprietary storage or specific formats, which leads to concerns about vendor lock-in and operational rigidity. Both Snowflake and Databricks have acknowledged these concerns and have taken steps to offer more open architectures. Snowflake introduced support for Apache Iceberg, allowing users to store data outside its proprietary format while maintaining the advantages of Snowflake’s analytical engine. Meanwhile, Databricks launched its Uniform Format (UniForm) feature, enabling Delta Lake tables to be read as Apache Iceberg or Apache Hudi tables. While these efforts represent a move toward more openness, they do not fully resolve the complexities of modern data architectures that frustrate organizations by making them choose between the two.. The Reality of Enterprise Data: It’s Everywhere No matter how compelling Snowflake and Databricks’ offerings may be, organizations will always have data residing in disparate locations. This is because enterprise data exists across on-premises databases and legacy data warehouses, cloud object storage in multiple formats (Parquet, Avro, ORC, etc. ), modern data lakes leveraging open standards and third party data sources shared via APIs or external storage. Given this reality, the idea that a single platform can act as the universal hub for all data is unrealistic. Different teams within an organization use different tools that fit their specific needs. Data science teams may leverage Databricks for AI workloads, while business intelligence (BI) teams prefer Snowflake for analytics, and operational teams rely on transactional databases. The challenge, then, is not choosing between Snowflake and Databricks but finding a way to unify and govern all data without unnecessary friction. The Future: Federated IT and Portable Data Catalogs Rather than engaging in the Snowflake vs. Databricks debate, forward-thinking organizations want a federated IT strategy. This approach embraces the diversity of data storage and processing solutions while ensuring seamless access and governance across the enterprise. At the heart of this transformation is the evolution of open and portable data catalogs. A modern data catalog is not just a metadata repository; it serves as the backbone of federated data access. It provides a unified view of data in the data lakehouse and governance and security policies that apply consistently regardless of where the data resides and is processed. Better yet, it offers interoperability with multiple query engines, enabling teams to use the best tool for their needs without migrating data. Projects like Apache Polaris, which powers both Snowflake’s Open Catalog and Dremio’s own built-in catalog, and Unity Catalog which serves as Databricks’ governance layer, are critical to enabling this shift. These catalogs establish a consistent layer for governance, curation, and query ability, ensuring data remains accessible and secure regardless of which tools different teams prefer. Delivering Data for BI and AI with Flexibility Interoperability across cloud and on-premises environments. A single, portable catalog layer that abstracts the complexity of multiple storage formats and query engines. Self-service capabilities for BI and AI teams, ensuring they can access trusted data without relying on centralized IT bottlenecks. By adopting a federated IT approach, organizations can empower their teams with the tools and platforms they prefer while maintaining a cohesive data strategy. This not only reduces vendor lock-in but also allows businesses to adapt to future data needs with agility and confidence. The Role of Data Products in a Federated IT Platform Beyond simply unifying data, a federated IT platform enables organizations to transform unified data into data products. Data products are governed, curated, and accessible datasets – or groups of datasets – managed with clear accountability, similar to how a product manager oversees traditional projects. These data products ensure that teams across the organization can rely on consistent, high-quality, and well-governed data for their specific use cases, whether for BI, AI, or operational analytics. A federated approach to IT should facilitate the creation and management of data products by enforcing governance policies that ensure data integrity, security, and compliance and by providing self-service data access with clear ownership and documentation. It also supports multiple storage formats and processing engines to cater to diverse needs and delivers an abstraction layer that enables data products to be consumed in a unified manner across different tools and platforms, By moving beyond just unifying data and focusing on creating consumable data products, organizations can extract greater value from their data and ensure that it meets the needs of various stakeholders. The Unanswered Question: How Will Federated Data Product Delivery Work? While the industry is moving toward a federated model for IT and data product management, an open and critical question remains: how can this be implemented at scale? Over the next few years, organizations and vendors will grapple with key challenges to address this by:: Standardizing data product definitions to ensure interoperability across tools. Implementing federated governance frameworks that work across cloud and on-prem environments. Developing automated pipelines for data product creation, maintenance, and distribution. Balancing flexibility with control to meet the needs of different teams while maintaining security and compliance. Companies are actively exploring different solutions that address these challenges, each offering their vision for the future of federated data product delivery. Open Table Formats & Lakehouse Catalogs: The Building Blocks of Federated Data Despite the uncertainties around implementation, the building blocks of federated data product delivery are beginning to take shape. Primitives like open table formats such as Apache Iceberg, Delta Lake, Apache Hudi and lakehouse catalogs like Apache Polaris, Unity Catalog provide the foundational pieces for a future in which federated IT enables seamless data product creation and management. Organizations that adopt these primitives can start building a more open, flexible, and interoperable data ecosystem, allowing them to ensure longevity and portability of dataacross different tools and platforms, and reduce reliance on proprietary storage formatsthat create vendor lock-in. The approach will also allow them to simplify governance and security policiesthrough a centralized catalog layer while enabling teams to query, analyze, and transform datawithout unnecessary complexity. The companies developing and pitching their version of this future are making their play for dominance in the evolving data architecture landscape. Organizations must carefully evaluate these offerings and prioritize open, flexible solutions that align with their long-term data strategy. Moving on from the Snowflake/Databricks dilemma: Embrace Federated IT & It Won’t Matter Rather than getting caught up in the battle between Snowflake and Databricks, organizations should recognize that the future of data architecture is neither platform-specific nor proprietary. The real opportunity lies in federated governance, interoperability, and a unified catalog layer that enables seamless data access and management across diverse environments. By embracing open standards and leveraging portable catalogs like Apache Polaris and Unity Catalog, businesses can future-proof their data strategies. This shift also allows for greater flexibility, improved collaboration, and an architecture that supports BI, AI, and other emerging workloads without compromising governance or control. In the end, organizations don’t need to choose a winner in the Snowflake vs. Databricks war—they need a data strategy that transcends it. Alex Merced Alex Merced is a Senior Technology Evangelist for Dremio, the unified lakehouse platform for self-service analytics and AI. He has worked as a developer and instructor for companies like GenEd Systems, Crossfield Digital, CampusGuard and General Assembly. Alex is passionate about technology and has put out tech content on outlets such as blogs, videos and his podcasts Datanation and Web Dev 101. Alex Merced has contributed a variety of libraries in the Javascript & Python worlds including SencilloDB, CoquitoJS, Dremio-simple-query and more. previous post
Databricks Frequently Asked Questions (FAQ)
When was Databricks founded?
Databricks was founded in 2013.
Where is Databricks's headquarters?
Databricks's headquarters is located at 160 Spear Street, San Francisco.
What is Databricks's latest funding round?
Databricks's latest funding round is Line of Credit.
How much did Databricks raise?
Databricks raised a total of $19.252B.
Who are the investors of Databricks?
Investors of Databricks include Morgan Stanley, Goldman Sachs, BNP Paribas, Blue Owl Capital, Barclays Bank and 73 more.
Who are Databricks's competitors?
Competitors of Databricks include Chalk, Datahub, Arize, Mindtech, DataPelago and 7 more.
Loading...
Compare Databricks to Competitors

DataRobot specializes in artificial intelligence and offers an open, end-to-end AI lifecycle platform within the technology sector. The company provides solutions for scaling AI applications, monitoring and governing AI models, and driving business value through predictive and generative AI. DataRobot serves various industries, including healthcare, manufacturing, retail, and financial services, with its AI platform. It was founded in 2012 and is based in Boston, Massachusetts.

Alteryx is a company specializing in enterprise analytics, providing a platform that facilitates data preparation and analytics processes. The company's products allow users to conduct data analysis, develop predictive models, and visualize data insights. Alteryx serves sectors that require data analytics capabilities, including financial services, retail, healthcare, and manufacturing. Alteryx was formerly known as SRC. It was founded in 1997 and is based in Irvine, California.

Cloudera operates in the hybrid data management and analytics sector. Its offerings include a hybrid data platform that is intended to manage data in various environments, featuring secure data management and cloud-native data services. Cloudera's tools are used in sectors such as financial services, healthcare, and manufacturing, focusing on areas like data engineering, stream processing, data warehousing, operational databases, machine learning, and data visualization. It was founded in 2008 and is based in Santa Clara, California.

Dataiku is an artificial-intelligence (AI) platform that integrates technology, teams, and operations to assist companies in incorporating intelligence into their daily operations across various industries. The platform provides tools for building, deploying, and managing data, analytics, and AI projects, including Generative AI, Machine Learning, data preparation, insights generation, and AI governance. Dataiku serves banking, life sciences, manufacturing, telecommunications, insurance, retail, public sector, utilities, energy, and healthcare sectors. It was founded in 2013 and is based in New York, New York.

H2O.ai specializes in generative AI and machine learning. It provides a comprehensive AI cloud platform for various industries. The company offers a suite of AI cloud products, including automated machine learning, distributed machine learning, and tools for AI-driven data extraction and processing. H2O.ai caters to sectors such as financial services, healthcare, insurance, manufacturing, marketing, retail, and telecommunications. H2O.ai was formerly known as 0xdata. It was founded in 2012 and is based in Mountain View, California.
DataPelago focuses on developing analytics solutions in the data industry. Its main offerings include a differentiated solution for extracting instantaneous insights from data, regardless of its scale, speed, or structure, with exceptional performance and cost efficiency. The company primarily serves sectors that require cutting-edge data processing and analytics capabilities. It was founded in 2021 and is based in Mountain View, California.
Loading...